Table of contents
Perquisites
For this we'll require, numpy and matplot lib:
Raw Data
Let's create linearly spaced x data from 0 to 21 in steps of 2 using the arange function and from this create a quadratic (2nd order polynomial) with coefficients 0.1, 1.2 and 5:
This can be done using the code above recalling that n*x is multiplication of n by x and x**n is x to the power of n.
Lets go ahead and plot this data as a green scatter plot:

Fitting a Polynomial using the Function polyfit
Let's try and fit this data to a 1st order polynomial otherwise known as a straight line. The equation for a straight line is:
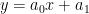
For a first polynomial, we require two coefficients, the first coefficient a0 is called the gradient and the second coefficient a1 is called the constant.
To fit this we can use the function polyfit which is called from the numpy library. The output arguments are the polynomial coefficients pn and n is the order:
In our case:
[ 3.2 -1. ]We can also explicitly specify our output arguments using:
3.1999999999999997
-1.0000000000000078Now let's try and fit using a 2nd order polynomial otherwise known as a quadratic function. Here the equation is:

This time we require 3 polynomial coefficients, one for the second order term, one for the first order term and one for the constant:
[0.1 1.2 5. ]Once again we can explicitly state the polynomial coefficients as outputs:
5.000000000000009
1.1999999999999986
0.10000000000000006We can go a step further and fit to a 3rd order polynomial also known as a cubic function. Here we require 4 coefficients, one for the third order term, one for the second order term, one for the first order term and one for the constant:

[1.77360529e-17 1.00000000e-01 1.20000000e+00 5.00000000e+00]Note the extremely low magnitude in the 3rd order term, meaning this data has effectively fitted to a 2nd order polynomial opposed to a 3rd order polynomial.
Evaluating a Polynomial at a DataPoint Using the Function polyval
We can evaluate the point at say x=1 using the function polyval. The inputs to this function are the polynomial coefficients as the datapoints:
We can try the linear fit with an x value of 1
2.199999999999992This point can be plotted:
As we can see it is quite far out:

If we want multiple points we can input a vector:
2.199999999999992
8.599999999999993Once again we can plot these datapoints:
As we can see the first point is quite far out but the second point is closer to what is expected:

Evaluating a Polynomial at a Series of DataPoints Using the Function polyval
For larger datasets it is easier if we don't explicitly state the polynomial coefficients individually. Recall when specifying the output of polyfit without square brackets we got a vector a opposed to the individual a0 and a1 when we used square brackets. We can input this value a as the first input to polyval i.e. can replace [a0,a1].
Next instead of explicitly stating the x values, we can create a vector of odd values using:
Now we can calculate the vector ylin using the vector x2 as an input argument:
We can once again plot these:

Now with the linear fit we can see the values don't exactly match up, this is expected as we are under-fitting a quadratic function (2nd order polynomial) with a linear fit (first order polynomial).
We can now try the quadratic (second order polynomial) coefficients using the same odd x values x2:
We can once again plot this:

Subplots of Multiple Fits
In general we would plot the fit as a line and not as a scatter. Let's create a plot with a subplot comparing linear (1st order), quadratic (2nd order), cubic (3rd order) and 4th order polynomial fits.

Using a DataFrame
It can also be quite useful to store the data and fitted data in a dataframe (table):


Evaluating your Fit using statsmodels
So far nothing much is said about the goodness of fit of the polynomial. To get more information, we can install a third party library called statmodels. Close down Spyder and open the Anaconda Powershell Prompt. Type in:

Press y to proceed:



To use the stats models you will need to import the statsmodels formula api as smf (this is normally done at the top of your script):
We need the Original Data DataFrame from above as well as the Polynomial Coefficients:
Now we need to create a polynomial function from the coefficients measured using polyfit, in this case f and load this formula in smf.ols (stats models formula – ordinary least squares) specifying the output y1 being this function f of x1. We need to specify the data as a dataframe and then specify that we want to fit.
In the background this will use the original x1 data to fit the polynomial using the coefficients given from the 1st order polyfit of the x1, y1 data. It will then use least squares on the calculated y values comparing them with the ordinary original y values:
OLS Regression Results
==============================================================================
Dep. Variable: y1 R-squared: 0.970
Model: OLS Adj. R-squared: 0.967
Method: Least Squares F-statistic: 295.4
Date: Wed, 07 Aug 2019 Prob (F-statistic): 3.44e-08
Time: 21:54:52 Log-Likelihood: -29.491
No. Observations: 11 AIC: 62.98
Df Residuals: 9 BIC: 63.78
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -1.776e-14 2.154 -8.25e-15 1.000 -4.873 4.873
model(x1) 1.0000 0.058 17.187 0.000 0.868 1.132
==============================================================================
Omnibus: 1.593 Durbin-Watson: 0.385
Prob(Omnibus): 0.451 Jarque-Bera (JB): 1.107
Skew: 0.566 Prob(JB): 0.575
Kurtosis: 1.936 Cond. No. 67.8Here the Adjusted R squared is 0.967 which is close to 1 indicating a good fit to the linear coefficients, however we can try the second order polynomial instead. Unsurprisingly the Adjusted R squared is now exactly 1.000 as this is a model polynomial with these exact coefficients.
OLS Regression Results
==============================================================================
Dep. Variable: y1 R-squared: 1.000
Model: OLS Adj. R-squared: 1.000
Method: Least Squares F-statistic: 8.684e+31
Date: Wed, 07 Aug 2019 Prob (F-statistic): 9.61e-141
Time: 22:08:36 Log-Likelihood: 343.54
No. Observations: 11 AIC: -683.1
Df Residuals: 9 BIC: -682.3
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -3.553e-15 3.99e-15 -0.890 0.397 -1.26e-14 5.48e-15
f(x1) 1.0000 1.07e-16 9.32e+15 0.000 1.000 1.000
==============================================================================
Omnibus: 2.870 Durbin-Watson: 1.359
Prob(Omnibus): 0.238 Jarque-Bera (JB): 0.466
Skew: -0.123 Prob(JB): 0.792
Kurtosis: 3.977 Cond. No. 67.4
==============================================================================Note over-fitting will also give an adjusted R squared of 1:
OLS Regression Results
==============================================================================
Dep. Variable: y1 R-squared: 1.000
Model: OLS Adj. R-squared: 1.000
Method: Least Squares F-statistic: 3.292e+31
Date: Wed, 07 Aug 2019 Prob (F-statistic): 7.56e-139
Time: 22:11:41 Log-Likelihood: 338.20
No. Observations: 11 AIC: -672.4
Df Residuals: 9 BIC: -671.6
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.421e-14 6.48e-15 2.192 0.056 -4.52e-16 2.89e-14
f(x1) 1.0000 1.74e-16 5.74e+15 0.000 1.000 1.000
==============================================================================
Omnibus: 15.376 Durbin-Watson: 0.888
Prob(Omnibus): 0.000 Jarque-Bera (JB): 9.005
Skew: 1.784 Prob(JB): 0.0111
Kurtosis: 5.629 Cond. No. 67.4==============================================================================
Dep. Variable: y1 R-squared: 1.000
Model: OLS Adj. R-squared: 1.000
Method: Least Squares F-statistic: 4.932e+31
Date: Wed, 07 Aug 2019 Prob (F-statistic): 1.23e-139
Time: 22:12:28 Log-Likelihood: 340.43
No. Observations: 11 AIC: -676.9
Df Residuals: 9 BIC: -676.1
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.421e-14 5.3e-15 2.684 0.025 2.23e-15 2.62e-14
f(x1) 1.0000 1.42e-16 7.02e+15 0.000 1.000 1.000
==============================================================================
Omnibus: 0.908 Durbin-Watson: 0.593
Prob(Omnibus): 0.635 Jarque-Bera (JB): 0.629
Skew: -0.057 Prob(JB): 0.730
Kurtosis: 1.834 Cond. No. 67.4
==============================================================================